Sentry - Log LLM Exceptions
This is community maintained, Please make an issue if you run into a bug https://github.com/BerriAI/litellm
Sentry provides error monitoring for production. LiteLLM can add breadcrumbs and send exceptions to Sentry with this integration
Track exceptions for:
- litellm.completion() - completion()for 100+ LLMs
- litellm.acompletion() - async completion()
- Streaming completion() & acompletion() calls
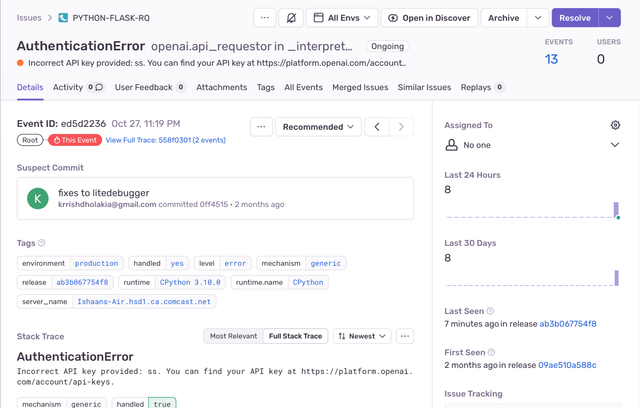
Usage
Set SENTRY_DSN & callback
import litellm, os
os.environ["SENTRY_DSN"] = "your-sentry-url"
litellm.failure_callback=["sentry"]
Sentry callback with completion
import litellm
from litellm import completion
litellm.input_callback=["sentry"] # adds sentry breadcrumbing
litellm.failure_callback=["sentry"] # [OPTIONAL] if you want litellm to capture -> send exception to sentry
import os
os.environ["SENTRY_DSN"] = "your-sentry-url"
os.environ["OPENAI_API_KEY"] = "your-openai-key"
# set bad key to trigger error
api_key="bad-key"
response = completion(model="gpt-3.5-turbo", messages=[{"role": "user", "content": "Hey!"}], stream=True, api_key=api_key)
print(response)
Sample Rate Options
SENTRY_API_SAMPLE_RATE: Controls what percentage of errors are sent to Sentry
- Value between 0 and 1 (default is 1.0 or 100% of errors)
- Example: 0.5 sends 50% of errors, 0.1 sends 10% of errors
SENTRY_API_TRACE_RATE: Controls what percentage of transactions are sampled for performance monitoring
- Value between 0 and 1 (default is 1.0 or 100% of transactions)
- Example: 0.5 traces 50% of transactions, 0.1 traces 10% of transactions
These options are useful for high-volume applications where sampling a subset of errors and transactions provides sufficient visibility while managing costs.
Redacting Messages, Response Content from Sentry Logging
Set litellm.turn_off_message_logging=True This will prevent the messages and responses from being logged to sentry, but request metadata will still be logged.
Let us know if you need any additional options from Sentry.